MySQL索引与存储方式对性能的影响
本文内容遵从CC版权协议, 可以随意转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明网址: http://www.penglixun.com/database/mysql_index_store_perfomance_effect.html
本文配图来自《高性能MySQL(第二版)》。
在数据库中,对性能影响最大的几个策略包括数据库的锁策略、缓存策略、索引策略、存储策略、执行计划优化策略。
索引策略决定数据库快速定位数据的效率,存储策略决定数据持久化的效率。
MySQL中两大主要存储引擎MyISAM和InnoDB采用了不同的索引和存储策略,本文将分析它们的异同和性能。
MySQL主要提供2种方式的索引:B-Tree(包括B+Tree)索引,Hash索引。
B树索引具有范围查找和前缀查找的能力,对于N节点的B树,检索一条记录的复杂度为O(LogN)。
哈希索引只能做等于查找,但是无论多大的Hash表,查找复杂度都是O(1)。
显然,如果值的差异性大,并且以等于查找为主,Hash索引是更高效的选择,它有O(1)的查找复杂度。如果值的差异性相对较差,并且以范围查找为主,B树是更好的选择,它支持范围查找。
Hash索引各种引擎大同小异,没有太多可探讨性,本文主要讨论不同形式的B树索引。
B树属于二叉平衡树,平衡树就是任何一个节点的左右节点高度差距不能超过1的树,这才是绝对平衡的树。
平衡树比较好的算法是AVL,它通过左旋、右旋及其组合的操作可以保证树绝对平衡。
下面是AVL算法中的全部旋转操作:
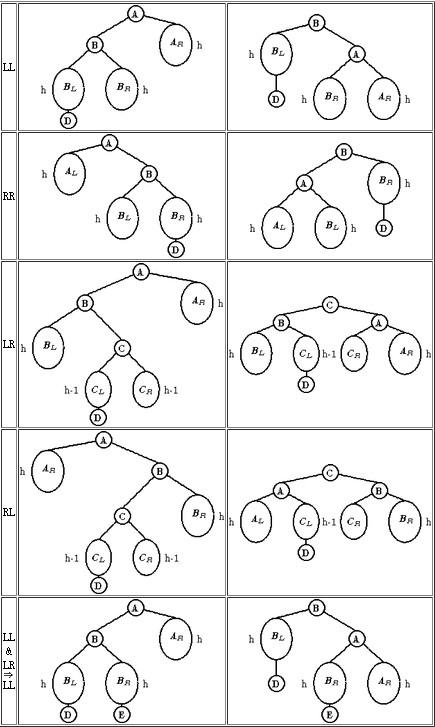
平衡树处在任何一个左边的不平衡状态都可以通过相应的旋转操作转移到右边的平衡状态。
数据库采用的B树只在叶子节点记录信息,非叶子节点记录的是范围信息,这是与一般搜索树不同的地方(一般搜索树非叶子节点也记录信息)。
这是一个B+树的结构,InnoDB的索引都采取了这种形式,它在B-树的基础上为每个叶子节点加了一个指针指向下一个叶子节点,这样可以快速的进行范围查找。
MyISAM是否也是B+树我还不能确定,但是B-树我没有想到可以快速进行范围查找的方法,应该也是B+树。
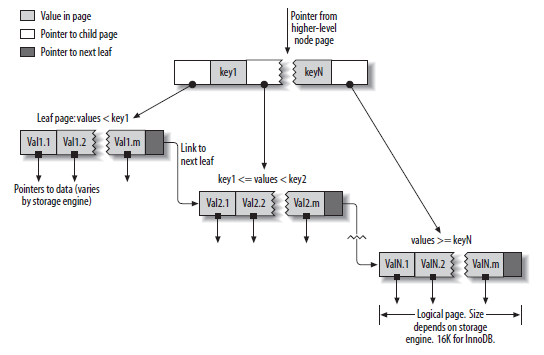
例如这个B+树的例子:

如果我要查找名字以A开头的全部信息,我只要获取第一个叶子节点,然后顺序沿着指向下一个叶子的指针,直到发现当年叶子节点已经不是以A开头则中止,这样只要搜索到第一个叶子节点(O(LogN))再沿着指针检索(O(N)),就可以获取全部索引,如果N个节点的表扫描M个连续值,就是O(LogN)+O(M),如果B-树则需要回溯到上层节点,这样最差的效率是O(LogN)*M。
对于InnoDB,使用了一种改进的B+树索引,称为聚集索引(Clustered Index),它的不同之处在于索引上不仅有索引值的信息,还有整个索引值所在行的信息,免去了一次通过索引值上的位置去取整行的操作。
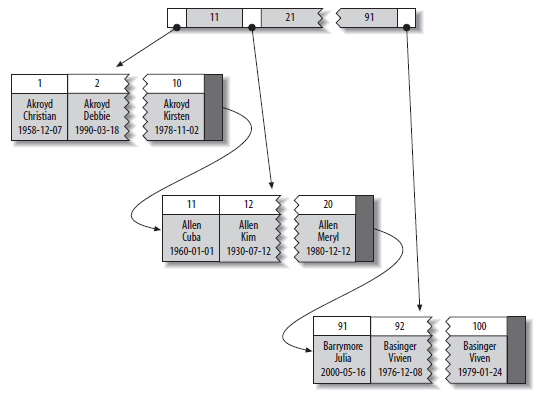
假设我们有个表有(col1,col2)列,col1是主键,col2也建立索引。那么在MyISAM引擎中,文件会被这样记录,因为MyISAM是按插入顺序把数据写入文件。如果有删除则空出位置,再次插入如果可以放下则会填充空白,对于不定长的行,存储引擎都会在分页中预留位置,以供更新更长的值(一般是VARCHAR),放不下则会添加到文件结尾,并从原位置删除。所以有时候会有空间浪费,需要Optimize Table来优化。
因此:定长的行比不定长的行效率高!把定长数据和不定长数据分开存储,很多时候可以提高效率。
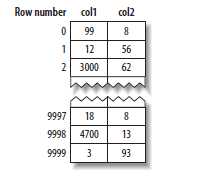
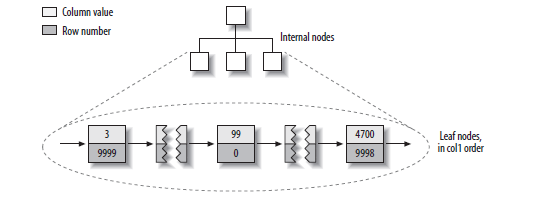
再来看MyISAM的主键索引,索引Key是主键值,索引Value是行的文件位置,通过这个位置可以直接读取行。从这个图上来看,MyISAM也是采用B+树。
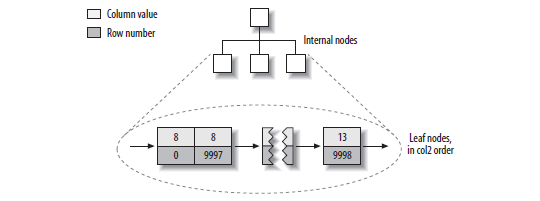
MyISAM的非主键索引,跟逐渐索引没有不同,也是索引行的文件位置。
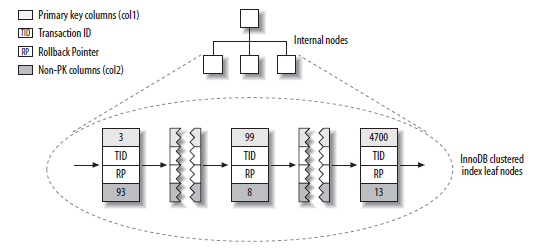
再看InnoDB的主键索引,索引Key是主键值,索引Value是整行的数据。
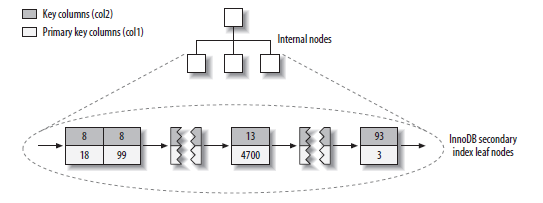
InnoDB的非主键索引,索引Key是列值,索引Value是主键值。
对比MyISAM和InnoDB的索引策略:
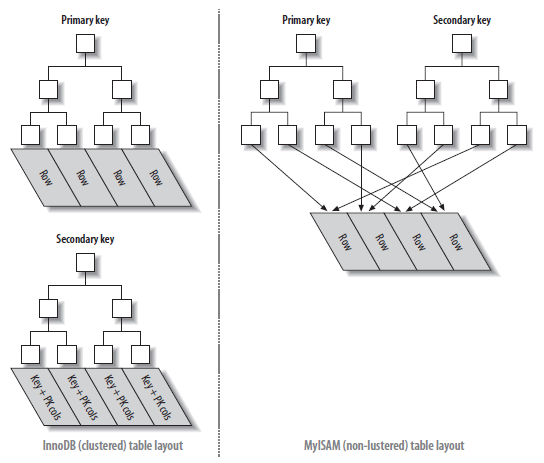
可以发现MyISAM所有列的索引都是一样,索引Key是列值,索引Value是行的文件位置。
InnoDB的主键索引包含了行的全部信息,索引Key是主键值,索引Value是整行的值。而非主键索引索引Key是列值,索引Value是主键值,取数据时到主键索引中取。
并且在InnoDB中,一个聚集索引是必须的,如果没有定义主键,InnoDB也会自己隐含的建立一个聚集索引作为主键,因为InnoDB的主键索引还有个重要的功能就是行锁,这在我的另一篇文章中分析过。
再来看看我们插入值时会发生什么:
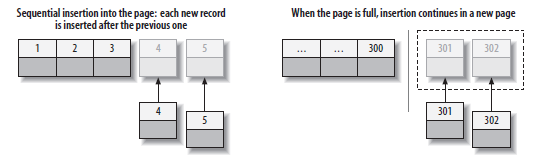
InnoDB会按主键索引顺序组织文件,如果按主键顺序插入,可以直接在最尾部加入。并且只填充页面的15/16,这样可以预留部分空间以供行修改,这样组织的数据是非常紧凑的。
如果主键不是顺序的,我们来看看会发生什么,因为要按主键顺序存放,数据会被不断地移动,调整页面。
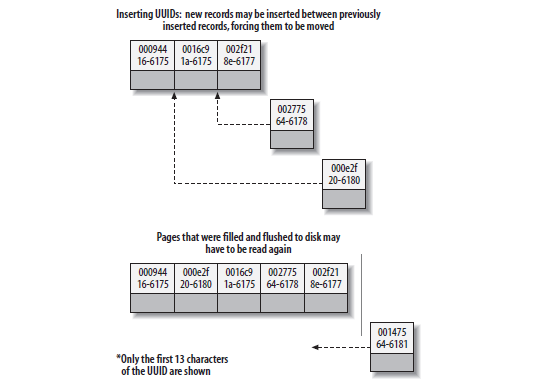
所以:InnoDB引擎按主键顺序插入记录是非常必要的,否则性能将会面临很大风险。

组合索引是怎样的结构呢?
组合索引也是一样,组合索引无非是单列拼接,建立索引和判断唯一性算法不变
你好,请问 innodb 使用联合主键,而联合主键的插入不是顺序的,这样是不是会影响性能?