数据库中的一些概念——集群技术及数据仓库
本文内容遵从CC版权协议, 可以随意转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明网址: http://www.penglixun.com/database/cluster_and_data_warehouse.html
最近学习数据库集群技术,遇到一些新的概念,于是总结一些这些新概念。
数据库与数据仓库的区别
简而言之,数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID。
单从概念上讲,有些晦涩。任何技术都是为应用服务的,结合应用可以很容易地理解。以银行业务为例。数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记帐。数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存款又多,消费交易又多,那么该地区就有必要设立ATM了。
显然,银行的交易量是巨大的,通常以百万甚至千万次来计算。事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。而分析系统是事后的,它要提供关注时间段内所有的有效数据。这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的了。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。那么,数据仓库与传统数据库比较,有哪些不同呢?让我们先看看W.H.Inmon关于数据仓库的定义:面向主题的、集成的、与时间相关且不可修改的数据集合。
“面向主题的”:传统数据库主要是为应用程序进行数据处理,未必按照同一主题存储数据;数据仓库侧重于数据分析工作,是按照主题存储的。这一点,类似于传统农贸市场与超市的区别—市场里面,白菜、萝卜、香菜会在一个摊位上,如果它们是一个小贩卖的;而超市里,白菜、萝卜、香菜则各自一块。也就是说,市场里的菜(数据)是按照小贩(应用程序)归堆(存储)的,超市里面则是按照菜的类型(同主题)归堆的。
“与时间相关”:数据库保存信息的时候,并不强调一定有时间信息。数据仓库则不同,出于决策的需要,数据仓库中的数据都要标明时间属性。决策中,时间属性很重要。同样都是累计购买过九车产品的顾客,一位是最近三个月购买九车,一位是最近一年从未买过,这对于决策者意义是不同的。
“不可修改”:数据仓库中的数据并不是最新的,而是来源于其它数据源。数据仓库反映的是历史信息,并不是很多数据库处理的那种日常事务数据(有的数据库例如电信计费数据库甚至处理实时信息)。因此,数据仓库中的数据是极少或根本不修改的;当然,向数据仓库添加数据是允许的。
数据仓库的出现,并不是要取代数据库。目前,大部分数据仓库还是用关系数据库管理系统来管理的。可以说,数据库、数据仓库相辅相成、各有千秋。
补充一下,数据仓库的方案建设的目的,是为前端查询和分析作为基础,由于有较大的冗余,所以需要的存储也较大。为了更好地为前端应用服务,数据仓库必须有如下几点优点,否则是失败的数据仓库方案。
1.效率足够高。客户要求的分析数据一般分为日、周、月、季、年等,可以看出,日为周期的数据要求的效率最高,要求24小时甚至12小时内,客户能看到昨天的数据分析。由于有的企业每日的数据量很大,设计不好的数据仓库经常会出问题,延迟1-3日才能给出数据,显然不行的。
2.数据质量。客户要看各种信息,肯定要准确的数据,但由于数据仓库流程至少分为3步,2次ETL,复杂的架构会更多层次,那么由于数据源有脏数据或者代码不严谨,都可以导致数据失真,客户看到错误的信息就可能导致分析出错误的决策,造成损失,而不是效益。
3.扩展性。之所以有的大型数据仓库系统架构设计复杂,是因为考虑到了未来3-5年的扩展性,这样的话,客户不用太快花钱去重建数据仓库系统,就能很稳定运行。主要体现在数据建模的合理性,数据仓库方案中多出一些中间层,使海量数据流有足够的缓冲,不至于数据量大很多,就运行不起来了。
OLTP与OLAP
人们对数据的处理需求可以分为两种类型,操作型处理(OLTP)和分析型处理(OLAP),传统的数据库主要是面向OLTP,注重数据的计算、记录的插入、删除、与修改,以及简单的查询和统计。它的主要任务是进行事务处理,所关注的是事务处理的及时性、完整性和正确性,而在数据的分析处理方面存在着严重的不足,主要表现在以下一些方面。
首先是集成性的缺乏。业务数据库系统的条块与部门分割,导致数据分布的分散化与无序化。业务数据库缺乏统一的定义与规划,导致数据的定义存在歧义;其次是主题不明确,建立数据库的目的就是为了满足事务处理的需要,库和表的定义与设计完全以此为基础而进行,对于数据分析而言,这些库和表无疑缺少明确的主题。又是需要分析的数据会分散的存储在不同的表和库甚至不同的数据库服务器中,想要对这些数据进行有效的分析是十分困难的。然后是分析和处理的效率低下,设计基于传统数据库的应用系统的核心准则,是要确保事务得到及时、准确的处理。因此,在业务数据库系统的构建过程中,除了库和表的精心设计之外,索引的建立、存储过程的优化等工作,也均以此为中心展开,这样虽然充分提高了事务处理的效率,但是数据分析处理的效率却无法得到保证。
传统数据库由于自身条件的限制,无法担当作为大规模数据综合分析平台的重任,企业的决策迫切需要有一种新的理论与技术来提供支持,这就是数据仓库技术。
数据仓库就是面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理层的决策过程,“面向主题、集成、随时间变化和非易失”是它的主要特点。
面向主题是数据仓库中数据组织的最基本原则。数据仓库中的所谓“主题”,是一个逻辑概念。在信息管理的层次上,主题就是从管理的角度出发,对数据进行综合分析而抽取的,需要做进一步分析的对象,数据仓库的构造过程首先就是确定主题的过程。数据仓库的设计者必须明确该数据仓库所支持的决策内容,即数据仓库的用途,并将决策内容归纳为若干个具体的易于利用数据进行组织加以分析的主题。
数据仓库中数据的集成性是指,在构建数据仓库的过程中,多个外部数据源内格式不同、定义各异的数据,按照既定的策略经过抽取、清洗、转换等一系列处理。最终构成一个有机的整体。传统业务处理程序的侧重点在于迅速、正确地处理所有业务,记录业务内容和处理结果,而不是对决策提供支持。数据仓库直接使用传统业务处理的结果,进行数据分析。
数据仓库中数据的非易失性,包括两个方面的含义,其一是指数据仓库内容的更新、追加等操作是不频繁的,一般基于一定的周期或条件阈值进行;其二是指,数据在导入数据仓库后,虽然也有删除更新等操作,但决定这种操作的阈值条件是较难满足的,这种情况的发生是非常罕见的。
数据的时变性,是指数据仓库的内容随时间的变化不断得到补充、更新。其实质就是建立业务数据与时间的对应关系,即以时间为坐标轴,对既定时间点的业务数据生成“快照”,各个时间点的快照连接起来,就构成了数据仓库内容的动态连续变化图,为决策者提供有效的依据。
从数据库到数据仓库,完成了数据挖掘的最重要一步,为数据挖掘接下来的步骤的顺利进行大好了基础。数据挖掘的各项操作都是在数据仓库的基础上进行的。数据仓库的构建是一门大学问。
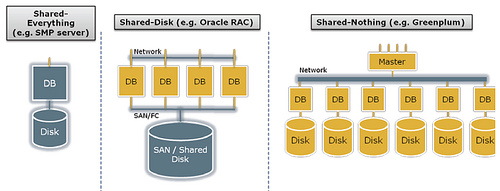
其实这也是很难说,目前数据库厂商中仅有oracle 提供share data模式群集(RAC模式),而其它数据库厂商的群集均是share nothing的模式,即群集中仅有一个节点处于活动状态,其它节点处于备用状态。Oracle的HA(OFS)其实就是就是采用share- nothing的一种群集模式,对于share-nothing和share-date (share-disk) 两种模式的差别,目前的确是有多种版本的说法。不过,采用share-nothing对于机器的利用率是相当低(如果只采用 active/standby模式),但如果采用active/active模式,则又会担心在一个节点出现故障时,另外一个节点是否能够承担原来两个节 点所承担的系统负载。对于share-data模式,大家目前比较关心的随着节点的增加,其内部通讯带来的系统开销(即cache同步等),则又是一个令 人担心的问题,特别是在OLTP系统上,所以,也有人建议,RAC还是用在data warehouse上比较好,而大型OLTP则还是不优先采用RAC,因为OLTP系统带来的内部通讯开销比较令人恐怖。
