数据库的拆分与合并
本文内容遵从CC版权协议, 可以随意转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明网址: http://www.penglixun.com/database/split_and_merge_database.html
数据库每天都承受着数据量的增长,慢慢的我们发现,对数据库得访问变得非常慢了,这个时候,不外乎两种做法:一是增加单机的配置,升CPU升内存升硬盘;二是“脑裂”,把数据库拆成多份分开存放。
第二个思路必然是最终的方案,因为无论如何单机的承受能力是有限的,业务量的增长必然最终还是要走第二条路。
其实拆分,并不是一个难事,按主键水平拆分,按列垂直拆分,操作上都难,最难的问题是发生在合并的时候,尤其是需要排序的时候(数据库的GROUP/DISTINCT也是先排序做的),合并会变得很麻烦。
一个很糟糕的办法是,设置一台排序专用的机器,访问数据库通过这台机器,发现要排序了就在本地排序,把结果转发给客户端。并发量一大,这台排序用的机器就悲剧了。
第二个方法是,我们希望我们从各个分库中拿出的数据,本身就是按我们所要的方式排序的,数据路由只要组装数据即可,不需要再次排序。
这个如何实现呢,来举个例子,假设我们有个社区系统,有一张用户表U(U_ID,Info,Date)三个字段,分别是主键、信息、注册时间。有一张关系表R(U_ID_1,U_ID_2),表示U_ID_1和U_ID_2是朋友。我们经常有这样的需求,想知道某个人有哪些朋友。
假设A和B是朋友,我们就在R表插入2条记录R(A,B),(B,A),为什么要两条呢,数据冗余啦!不错,就是要冗余,冗余可以让后面的工作很Easy。
现在数据量大的惊人,要拆表!
假设业务需求如下:
1. 用户的U.Info查询很少,但是这个部分很长。
2. 经常用U.Date经常被用来排序。
3. 经常要知道某个人有哪些好友。
4. 凡是显示用户都按注册先后排序。
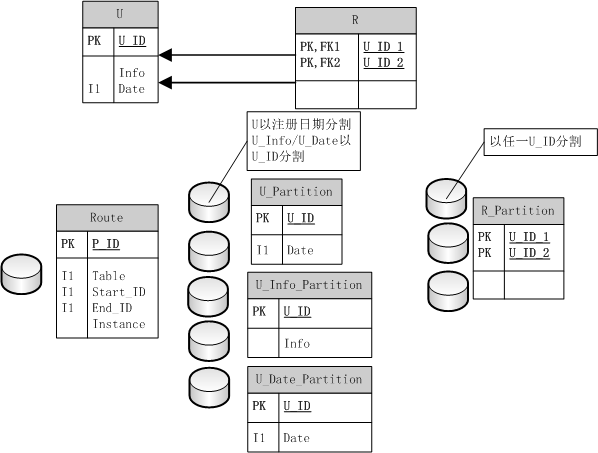
那么怎么拆捏,首先第一个需求,Info查询少,实际中这部分可能包含VARCHAR、TEXT等文本字段,最好需要把它们拆分出去,单独成表,可以提高效率,因为它们不常用。U被拆分为U(U_ID,Date),U_Info(U_ID,Info),U_Date(U_ID,Date)。为什么这样拆分?Date不是冗余了嘛,还是为了效率,制造冗余。
然后表怎么拆分呢,当然水平拆分,按ID?那要按Date排序的时候,就悲剧了,所以可以这么分:
U表按Date分区,U_ID建立索引;U_Info/U_Date表按U_ID分区。
这样分区什么好处?为了第2和4个需求,知道了要显示的用户ID列表,到U_Date去拿Date,然后到U表去访问,因为有拆分,所以到所需的时间范围所在的实例去读出新的ID序列,这样拿到的ID就是有序的,原来的ID可以抛弃了,用新的ID序列去拿可能需要的Info,这样取出的数据就是有序的。
然后R表怎么拆呢,很简单,按U_ID_1或者U_ID_2拆都可以,为什么?因为制造了冗余,两边都是对称的,从哪边取都能获得一个人的全部好友,所以就没关系了。
这样还是有一点不方便,拆分可能扩容,怎么办,不能每次都改程序吧?这好办建立1个分区路由表,记录下所有的分区信息,这样查询前先查分区表,再去相应的实例上取数据。
于是得到Schema的设计如下图:
当需要查询A用户的全部好友并且显示列表,再获取第一个好友的详细信息,我们就这么做:
1. 从Route路由表查找A用户所在实例名:SELECT instance FROM Route WHERE Start_ID >= A AND End_ID <=A AND Table = 'R'。
2. 拿到了Instance,就连接到相应的实例去:SELECT U_ID_2 FROM R WHERE U_ID_1 = 'A'。
3. 根据拿到的U_ID,再查所在的Instance,:ELECT instance FROM Route WHERE Start_ID >= u_id_2 AND End_ID <=u_id_2 AND Table = 'U_Date'。
4. 根据拿到的Instance,连接上去,去查U.Date:SELECT Date FROM R WHERE U_ID in (u_id_2)。
5. 有了U.Date,就可以到U去重新查询排序好的ID:SELECT U_ID FROM U WHERE Date in (date);
6. 然后拿列表中的第一个ID,去取U.Info,查Instance:SELECT instance FROM Route WHERE Start_ID >= u_id AND End_ID <=u_id AND Table = 'U_Info'。
7. 根据拿到的Instance,连上数据库去取Info:SELECT Info FROM U_Info WHERE U_ID = u_id;
所有任务完成,没有任何的排序产生。
这样大费周折值得吗,我觉得值得,当数据量大的惊人的时候,不可能在中间节点排序,只能是取出的数据就要有序,那么这种拆分思想,就是可以避免排序的。
有了思路,我会自己做一个小实验验证我的方法可行性和效率。

更新这些表的时候,如何保证数据一致?
尤其是万一发生数据库故障的情况下
@飘香一剑, 可以通过XA事务,分段提交。先预提交,全部预提交成功再进行全局提交。Oracle和InnoDB都支持XA事务。
挺不错 聊完就懂得去写成文字 以及思考下
建议XA事务就别用了….学会把放弃一些数据的完整性,分场景去使用.
补充下:
而且应用场景合适 以及 结构设计与程序处理设计合理,可以避免绝大部分时间 出现数据不完整的情况。
好好写,看好你小子!
楼主,上面的图片不能显示,能否修正下.
Flickr被墙了么……
2. 拿到了Instance,就连接到相应的实例去:SELECT U_ID_2 FROM R WHERE U_ID_1 = ‘A’。
取出的是个数据集合,那得连多少次数据库
这点代价跟扩展单台机器性能的耗费比起来,微不足道。
1. 我想问一下,Router表的作用是什么呢?我个人的理解是,通过水平拆分,将原先一张大表中的数据拆分到了多个表中。比如,U_Info表原先有1000条记录,拆成10张表以后,每张表100条记录,id分别从0-99,100-199,。。。,f分别对应了拆分之后的数据表U_Info_0,U_Info_1,。。。。中的记录;然后,每次查询的时候,通过主键匹配,看对应的记录落在那个数据表里面,是这个意思吗?