1989年11月10日,P.Linux闪亮登场,2009年11月10日,终于走完了第一个20年,在此记录一下。
1990~1991,太小,没回忆。
—-学前阶段—-
1992年,3岁,幼儿园小班。
记的当初是被妈妈拉着去幼儿园的,打小我就不喜欢上学。记得应该是这个时候,爸爸去了广东打工。
1993年,4岁,幼儿园中班。
妈妈腰经常痛,我立志要当军官,让警卫照顾妈妈,这个志向一直持续了十余年直到国防科大梦想的破灭。
1994年,5岁,幼儿园大班。
看动画片知道有机器人这种东西,跟妈妈说,我要做一个机器人帮妈妈做家务,这个志向一直持续到现在,一直对人工智能的东西感兴趣。这个时候知道了银河巨型机这种东西,知道是国防科大搞的,结合我的两个志向,决定以后上国防科大,国防科大就是未来十余年我奋斗的目标。
1995年,6岁,进入小学学前班。
记得这个时候,外婆去世了,外婆照顾了我很久,陪我睡觉的时候去世的,当时小,蒙了,后来才一直哭。
—-小学阶段—-
1996年,7岁,升入小学一年级。
这个时候应该是有门课叫自然,非常喜欢,对自然科学的兴趣就是这个时候产生的。
好像还一门课叫社会,对人文科学的兴趣是看社会课本产生的。
1997年,8岁,升入小学二年级。
没有什么特殊的事情,不知道是不是这个时候,跟我的同桌,有一次好几门课都是同时第一,很多人说我们抄袭~我X……
1998年,9岁,升入小学三年级。
这个时候开始有了数学奥赛,开始周末去补课,第一次知道补课,此后补课一直伴随我~
也是这一年,爸爸从广东带了电脑给我,我第一次碰了电脑,开始很喜欢打一个射击游戏,很原始,都打通关了。此后很长一段时间都打游戏。学习开始不太行,不过打游戏练就了我极快的反应能力和敲键盘速度,对以后的发展是好是坏说不清
1999年,10岁,升入小学四年级。
游戏玩腻了,不晓得在什么地方知道了Red Hat这种东西,就跑去电脑城买光盘,Red Hat 6吧好像,就买了一张回家,不知道怎么折腾的,就给装上了……此后就知道了Linux这个东西~在Win98和RH6的抉择中,因为老爸帮我装了Win98,就放弃RH6了,要是当年一直用RH,早就成Linux专家了。
2000年,11岁,升入小学五年级。
要竞赛了,我的数学却开始不行了,班主任施老师那个郁闷~
不过很意外,比赛完我觉得没戏了,却意外得了二等奖,排名还比较前,差一点就一等奖。
这一年就是先郁闷,然后意外的惊喜。
阅读全文…
标签:
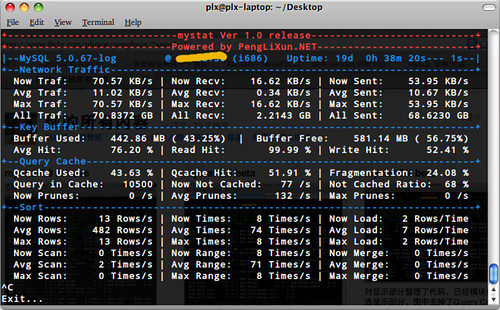
mystat是一款MySQL数据库实时监控脚本,Perl编写,基于MySQL的show global status和show global variables结果进行分析实时显示。能通过参数控释轮询间隔、轮询次数、监控项目。使用了strict;DBI;Switch;DBD::mysql;Getopt::Std;Term::ANSIColor;这几个Perl模块,通过CPAN都可以安装。
我已经尽力测试Bug,不过使用场景各异,如果发现Bug,请联系我,penglixun(at)gmail.com。
脚本包括如下参数
-i 轮询间隔 默认1s
-c 轮询次数 默认无限
-n 监控项目 默认basic
包括: all(全部项目), basic(基本项目), innodb(InnoDB项目), myisam(MyISAM项目)四个套装
以及下面的单项:
traffic – Network Traffic
kbuffer – Key Buffer
qcache – Query Cache
thcache – Thread Cache
tbcache – Table Cache
tmp – Temporary Table
query – Queries Statistics
select – Select Statistics
sort – Sort Statistics
innodb_bp – InnoDB Buffer Pool
项目之间可能有交叉的部分,取最大并集。
-d 取消项目 默认noneDB
包括: var(变量部分), innodb(InnoDB部分), none(无)
同时跟-n出现一样的项目,则优先处理-d。也就是说-n innodb -d innodb,不会显示innodb的部分。
-h 主机名 默认空
-u 用户名 默认空
-p 密码 默认空
例如:perl mystat.pl -n traffic,qcache,kbuffer,sort -d var -h 127.0.0.1 -u cactiuser -p cacti
显示如下
猛击这里下载:
 mystat.pl (56.8 KiB, 5,947 hits)
mystat.pl (56.8 KiB, 5,947 hits)
阅读全文…
这些天看数据仓库的内容,发现一个新内容——列式存储。曾经有想过把数据库行列转置作成索引,不过没有深想,没想到列式数据库已经开始发展起来了。
首先看下WIKI上对列式数据库的解释:
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合与批量数据处理和即席查询。相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合与小批量的数据处理,常用于联机事务型数据处理。
数据库以行、列的二维表的形式存储数据,但是却以一维字符串的方式存储,例如以下的一个表:
EmpId Lastname Firstname Salary
1 Smith Joe 40000
2 Jones Mary 50000
3 Johnson Cathy 44000
这个简单的表包括员工代码(EmpId), 姓名字段(Lastname and Firstname)及工资(Salary).
这个表存储在电脑的内存(RAM)和存储(硬盘)中。虽然内存和硬盘在机制上不同,电脑的操作系统是以同样的方式存储的。数据库必须把这个二维表存储在一系列一维的“字节”中,又操作系统写到内存或硬盘中。
行式数据库把一行中的数据值串在一起存储起来,然后再存储下一行的数据,以此类推。
1,Smith,Joe,40000;2,Jones,Mary,50000;3,Johnson,Cathy,44000;
列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据,以此类推。
1,2,3;Smith,Jones,Johnson;Joe,Mary,Cathy;40000,50000,44000;
这是一个简化的说法。
昨天装了下两个基于MySQL的数据仓库,infindb和infobright,看了文档发现它们都是列式数据库,把40多M的数据导入infobright,没想到数据文件只有1M多,压缩比令我惊讶!
然后测试了下选择某一列,在列上做计算,都比MyISAM和InnoDB要快,看了一些原理文档,就自己模拟了一下,写了个程序测试。
从内存中读取效率很高,但是从磁盘中读取(假设行式数据库的索引在内存中)比行式数据库要慢(开始在Twitter上说比行式快是程序写错了),不过我觉得还是我设计上的问题,至少Infobright就比MyISAM/InnoDB快,列式应该也有其特殊的索引机制和缓存机制,例如每列分开存在不同的文件,这样文件指针转移会更快。
2010-02-04补充:采用了多个文件指针后,列式存储明显加速,如果给每个列一个文件指针,效率会非常高,也可以肯定,如果每个列单独存储一个文件,效率还会提高。现在文件中列式表读取效率降低了4/5,接近行式表了。继续优化还能提高。
阅读全文…
以下内容不少来自Wiki和网络,整理了一下相关的概念。
数据仓库:Data Warehouse(DW),一种信息系统的数据存储理论,此理论强调利用某些特殊数据存储方式,让所包含的数据,特别有利于分析处理,以产生有价值的信息并依此作决策。利用数据仓库方式所存放的数据,具有一但存入,便不随时间而更动的特性,同时存入的数据必定包含时间属性,通常一个数据仓库皆会含有大量的历史性数据,并利用特定分析方式,自其中发掘出特定信息。
主要功能乃是将组织通过信息系统之在线交易处理(OLTP)经年累月所累积的大量数据,通过数据仓库理论所特有的数据存储架构,作一有系统的分析整理,以利各种分析方法如在线分析处理(OLAP)、数据挖掘(Data Mining)之进行,并进而支持如决策支持系统(DSS)、主管信息系统(EIS)之建立,帮助决策者能快速有效的自大量数据中,分析出有价值的信息,以利决策拟定及快速回应外在环境变动,帮助建构商业智能(BI)。
一般来说,数据仓库可由关系数据库,或专为数据仓库开发的多维度数据库建立,若由多维度数据库建立而成,其架构可分为星状及雪花状架构,包含数个维度数据表,及一个事实数据表。
数据超市:Data Mart(DM),数据仓库的特殊形式。正如数据仓库,资料超市也包含对操作数据的快照,便于用户基于历史趋势与经验进行战略决策。两者关键的区别在于资料超市的创建是在有具体的、预先定义好了的对被选数据分组并配置的需求基础之上的。配置资料超市强调对相关信息的易连接性。
在线分析处理:On-Line Analytical Processing(OLAP),一套以多维度方式分析资料,而能弹性地提供积存(Roll-up)、下钻(Drill-down)、和枢纽分析(pivot)等操作,呈现整合性决策资讯的方法,多用于决策支持系统、商务智能或数据仓库。其主要的功能,在于方便大规模数据分析及统计计算,对决策提供参考和支持。
阅读全文…
中国的互联网从无到有,从小到大,经过互联网泡沫的洗牌,坚持下来的门户脱颖而出,各种互联网客户端也各有各的地盘。
就目前而言,中国互联网上,能互相抗衡的巨头有腾讯,百度,阿里巴巴这三国鼎立,后起之秀有360和迅雷、盛大也不可小觑,不是不可能形成春秋五霸战国七雄的混战形式。
腾讯的杀手锏毫无疑问就是QQ,QQ在中国的强势地位令任何一家做IM的公司汗颜,在中国推动任何IM,基本属于找死,QQ牢牢掌握住了大部分用户,靠高端用户(有些我觉得是脑残)充值Q币、玩游戏来赚取收入。腾讯的用户体验牢牢抓住中国本土化的特点,这是进军中国的国际大企业一直忽略的地方,也是他们无法开拓中国市场的原因。腾讯一直在模仿,一直在超越,仿谁都能仿的好,这也不得不承认是抄出境界了。
百度的杀手锏毫无疑问就是搜索,百度的用户群都来自它的搜索用户,同样根据中国国情,百度做的非常有中国特色,因而即使Google这样的巨头,竞争中完全不带优势,尽管技术上Google绝对占尽优势。百度庞大的用户群令百度也想进军IM领域分这块蛋糕,也想进入电子商务领域分一杯羹,可惜从目前来看都不怎么样,百度的模仿能力还是稍逊腾讯一筹,而且百度没有腾讯的客户端优势,腾讯赚的是在线,百度赚的是点击。
阿里的杀手锏毫无疑问就是淘宝支付宝,B2B虽然比C2C赚钱,但是淘宝的用户基础还是靠淘宝和支付宝来支撑的。eBay在中国败北,也是不懂中国国情,没有先积攒用户、培养用户的网上购物习惯,就开始收费,这只能让犹豫淘宝还是eBay的商家毫不犹豫的选择了淘宝。淘宝有了用户,培养了用户的习惯,自己就成了标准,要做电子商务,就得按淘宝的模式来,用户习惯了这样。eBay在想卷土重来,已经没有机会。
阅读全文…
